- More
- Download
利用大模型自动填写跨境汇款合规申报单据的提效实操





Image Source: pexels
你在跨境汇款合规申报中,常常面临信息繁杂、审核压力大和人工填报出错等问题。大模型自动填写技术能够帮助你显著提升效率,减少人工操作带来的失误,实现合规审查流程的系统化和可解释化。根据实际应用反馈,采用大模型后,自动匹配率可达95%以上,财务关闭时间可缩短50%至60%。在实际落地时,自动填写更适合放在“资料整理、字段抽取、规则校验”这些前置环节,而资金执行仍应交给合规通道完成。像 BiyaPay 这类多资产交易钱包,本身覆盖跨境支付、资金管理与多币种兑换场景,适合作为后续 汇款 执行入口;在正式提交前,也可先借助其 汇率查询与对比工具 核对金额与换汇成本,让申报信息与实际资金路径更容易保持一致。下表展示了大模型自动填写在效率提升方面的部分核心数据:
| 指标 | 传统系统匹配率 | GPT-4 预期匹配率 | 备注 |
|---|---|---|---|
| 自动匹配率 | 70% - 90% | 95% 及以上 | 可能捕捉边缘案例 |
| 财务关闭时间缩短 | N/A | 50% - 60% | AI可提前捕捉问题,缩短关闭周期 |
核心要点
- 大模型自动填写技术能提升跨境汇款合规申报效率,自动匹配率可达95%。
- 采用自动化流程可减少人工操作,降低错误率,确保合规审查的准确性。
- 系统自动加载最新合规政策,确保申报信息符合各国监管要求,避免申报失败。
- 通过实时数据验证和多重校验,提升数据安全性,防止身份盗用和数据泄露。
- 持续评估和优化模型表现,确保系统高效、合规、安全,适应业务变化。
传统流程痛点

Image Source: pexels
合规申报复杂性
你在跨境汇款合规申报时,常常需要面对多重监管要求和复杂的业务流程。不同国家和地区对申报信息的标准、格式和内容有严格规定。你必须准确理解每一项政策,确保所有数据符合最新法规。行业报告显示,银行等待受益人报告关键信息,容易导致资金到账延迟。受款机构在完成外汇管制流程前,汇款也会被暂时扣留。这些流程环节增加了合规风险,也拉长了整体处理周期。
| 痛点 | 说明 |
|---|---|
| 监管要求 | 银行等待受益人报告某些信息,导致资金到账延迟。 |
| 汇款机构的处理延迟 | 受款机构在完成外汇管制流程之前,汇款被暂时扣留。 |
| 本地支付格式要求 | 受款方要求不同的支付消息标准或结构,导致信息不完整或缺失。 |
信息采集与录入低效
你在信息采集和录入环节,往往需要手动整理大量资料。传统流程依赖人工收集、核对和输入数据,容易出现信息遗漏或格式不符。缺乏实时支付系统,汇款在非工作时间到达时,支付会被延迟到下一个工作日处理。技术限制下,许多环节无法自动化,进一步影响整体效率。你会发现,信息流转速度慢,数据准确性难以保障。
你如果采用大模型自动填写,可以显著提升信息采集和录入的自动化水平,减少人工干预,提升整体效率。
人工操作易错
你在人工操作过程中,容易因疲劳、疏忽或对政策理解不一致而产生错误。手动处理数据时,格式、内容和逻辑校验难以做到全覆盖。行业报告指出,技术限制导致必须手动处理的情况依然普遍,直接影响支付速度和准确性。即使引入新技术,如果无法自动化受益人环节,支付速度提升依然有限。你需要投入更多时间进行复核和修正,进一步增加了运营成本和合规风险。
大模型自动填写流程
数据采集与预处理
你在跨境汇款合规申报中,首先需要面对多源异构数据的采集与预处理。大模型自动填写流程会自动从上游业务系统、支付通道、客户资料库等多渠道抓取原始数据。系统会对数据进行修正,确保信息完整一致,提升整体合规性。你还可以通过验证框架对数据准确性进行初步筛查,剔除无效或异常信息。预处理层会对输入数据进行清洗,去除冗余字段和格式错误,直接影响后续筛查和对账的准确性。高质量MX数据能够提升制裁匹配的精度,增强反欺诈能力。针对反洗钱(AML)场景,系统会补充上下文信息,满足监管要求。你可以参考下表,了解常见数据类型及其在流程中的作用:
| 数据类型 | 重要性描述 |
|---|---|
| 上游数据修正 | 确保数据的完整性和一致性,提升合规性。 |
| 验证框架 | 用于确保数据的准确性和合规性。 |
| 预处理层 | 确保输入数据的清洁度,直接影响筛查和对账的准确性。 |
| 高质量MX数据 | 提高制裁匹配的精确度,增强反欺诈评分。 |
| AML场景的上下文 | 提供更好的合规性背景,满足监管要求。 |
你通过自动化的数据采集与预处理,能够为后续的语义解析和规则建模打下坚实基础,显著减少人工介入和初步错误。
语义解析与实体识别
在数据预处理完成后,你需要依赖大模型对文本信息进行深度语义解析和实体识别。大模型自动填写系统会自动识别汇款人、收款人、地址、账户信息、交易金额等关键实体。你可以利用大型语言模型(如Claude3、GPT-4)在自然语言处理领域的强大能力,自动完成命名实体识别(NER)和关系抽取(RE)等任务。系统会结合条件随机场(CRF)、双向长短期记忆网络(BiLSTM-CRF)等算法,提升法律和金融领域实体提取的准确率。预训练模型(如BERT、GPT-2)在语义解析和实体识别方面表现优异,能够处理复杂的非结构化文本和多语言场景。
你在实际操作中,会发现大模型能够自动识别文本片段中的命名实体,并准确提取其属性。随着深度学习技术的发展,命名实体识别已成为合规自动化流程中的关键环节。你无需手动标注和抽取,大模型会自动完成信息抽取,极大提升效率和准确率。
- 大型语言模型在多语言实体识别中的F1值普遍超过0.85,展现出强大的统一表征能力。
- 你可以依赖大模型处理非结构化、语义隐含的信息,尤其在新型风险形态识别方面具有明显优势。
合规规则建模
你在合规申报过程中,必须严格遵循各国监管机构的规则和标准。大模型自动填写系统会自动加载最新的合规政策和业务规则,构建知识图谱和规则引擎。你可以通过系统自动匹配申报字段与合规要求,确保所有数据项均符合ISO、SWIFT等国际标准。系统会根据不同国家和地区的监管要求,自动调整字段格式和内容,避免因规则不符导致的申报失败。
你无需手动维护复杂的规则库,系统会自动更新和优化合规规则。大模型能够根据历史案例和最新政策,动态调整规则映射逻辑,提升高风险交易的覆盖率。你可以通过知识建模和规则推理,实现端到端的自动化合规审查,显著降低误报率和人工复核占比。
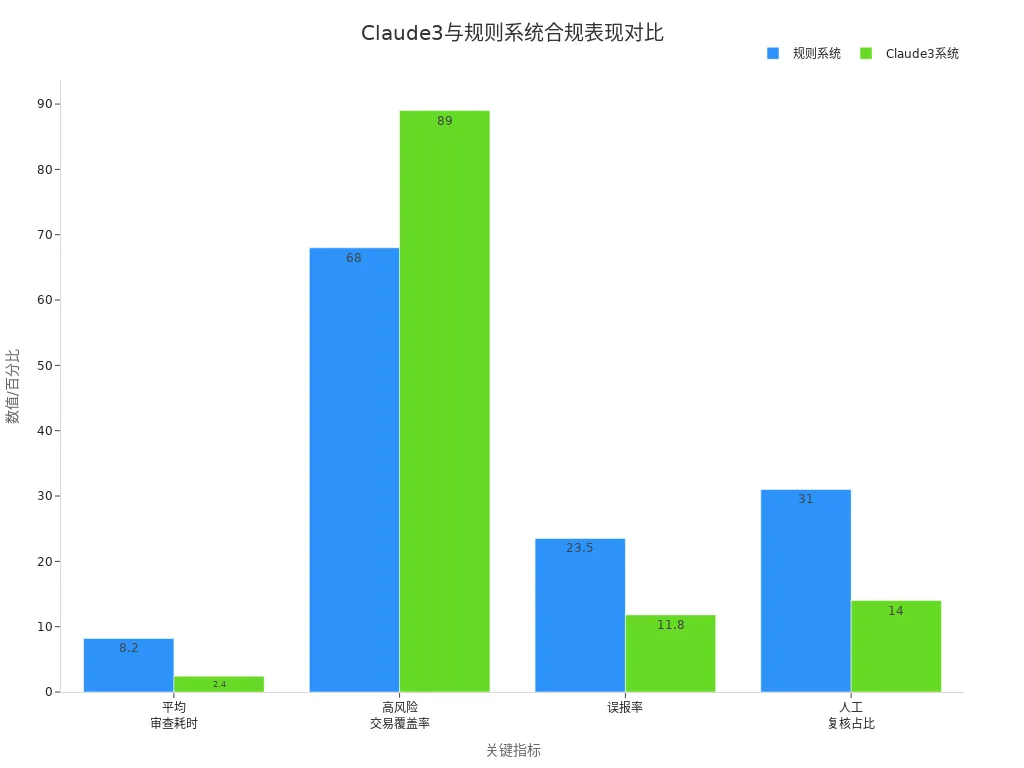
从上图可以看出,采用大模型自动填写后,平均审查耗时缩短至2.4秒,高风险交易覆盖率提升至89%,误报率下降至11.8%,人工复核占比降至14%。你可以直观感受到效率和准确率的双重提升。
自动填写与校验
在完成数据采集、语义解析和规则建模后,系统会自动将合规数据填写到申报单据中。你无需手动输入,系统会根据实体识别结果和规则映射,自动生成结构化申报内容。填写完成后,系统会自动进行多重校验,确保所有字段均符合监管要求。你可以参考下表,了解常见的校验规则:
| 验证规则 | 描述 |
|---|---|
| 名称 | 必须不为空且字符数 <= 140 |
| 地址 | 必须结构化(不再支持非结构化地址) |
| BIC | 必须是有效的SWIFT代码 |
| LEI格式 | 必须遵循ISO 17442 |
| 国家和货币代码 | 仅限ISO标准代码 |
| 非法字符 | 不允许有非法/不可打印字符 |
| 日期 | 必须合乎逻辑(YYYY-MM-DD) |
你通过自动填写与校验,能够大幅降低因手工操作导致的格式错误和合规风险。系统会自动提示异常字段,支持你快速修正,确保申报材料一次性通过合规审查。大模型自动填写不仅提升了整体效率,还为你带来更高的准确率和合规保障。
关键技术与实操
实体识别与语义理解
你在跨境汇款合规申报中,首先需要依赖大模型自动填写系统对多源数据进行实体识别和语义理解。系统会自动抽取汇款人、收款人、账户、地址、金额等关键信息,准确区分不同类型的实体。你可以利用预训练语言模型处理非结构化文本,提升命名实体识别的准确率。系统还会结合上下文,理解汇款目的、资金流向等深层语义,帮助你自动完成信息抽取和归类。
你在实际操作中,只需上传原始申报材料,系统会自动完成实体标注和语义解析,极大减少人工干预。
规则映射与风险检测
你在合规申报过程中,必须确保所有数据项符合最新监管要求。系统会自动将结构化数据与合规规则进行映射,动态检测潜在风险。你可以通过以下方式提升风险识别能力:
- 使用AI驱动的数据提取引擎,将汇款建议、支付指令、SWIFT MT和ISO 20022消息自动转换为结构化数据。
- 动态风险检查会基于支付地理位置、声明目的和对方风险档案,应用智能规则进行实时筛查。
- 实体图链接技术能够为你创建文档和交易活动的连接视图,揭示地理或参与方的重复异常模式。
你在日常操作中,可以实时发现高风险交易,系统会自动提示异常,支持你快速决策和干预。
决策可解释性与系统集成
你在合规自动化流程中,决策的可解释性和系统集成能力同样重要。系统会为每一步决策提供详细解释,帮助你追溯每一项合规判断的依据。你可以参考下表,了解常用方法的准确率:
| 方法 | 准确率 | 备注 |
|---|---|---|
| 规则解释 | 97% | 分类准确率 |
| 数据提取工具选择 | 97% | 正确选择率 |
| 规则执行 | 97.7% | 显著优于基线 |
你可以通过实施结构化策略,确保大模型输出的准确性和可靠性。系统会持续优化最佳实践,将大模型自动填写从实验工具转变为合规自动化的核心资产。你在集成现有业务系统时,可以无缝对接,提升整体运营效率和合规水平。
风险防控与合规保障

Image Source: pexels
数据安全与隐私
你在跨境汇款合规申报自动化过程中,必须高度重视数据安全与隐私保护。系统通过数字身份实时验证企业的合法性和财务状况,无需纸质文件,显著降低身份盗用和伪造风险。标准化的数字身份框架能够简化并保护跨境支付流程,防止数据泄露。你还可以依赖反洗钱和了解你的客户等程序,进一步提升数据安全性,确保敏感信息在传输和存储环节均受到加密和严格访问控制。
- 数字身份实时验证企业,防止欺诈和伪造
- 标准化框架简化跨境支付,提升数据安全
- 反洗钱和KYC程序保障信息合规
合规性与人工干预
你在自动化合规申报流程中,仍需关注合规性和人工干预的平衡。代理AI能够帮助你规避多司法辖区的制裁、欺诈和监管风险,并自动维护完整的审计跟踪,记录每一次决策所依据的数据和规则。你在处理复杂或例外情况时,人工干预依然不可或缺。合规团队可对高风险交易进行复核,确保系统输出的每一项决策均可追溯和解释。
- 代理AI自动规避制裁和监管风险
- 审计跟踪记录决策依据,提升透明度
- 人工干预处理例外,保障合规性
效果评估与持续优化
你需要通过多维度指标持续评估自动化系统的效果,并不断优化模型表现。常用评估指标包括准确性、相关性、一致性、延迟和效率、用户反馈等。你可以定期更新数据集,确保模型紧跟业务和监管变化。通过反馈循环和A/B测试,你能够持续提升模型的响应质量和合规能力。
| 指标 | 描述 |
|---|---|
| 准确性 | 输出与权威知识集或基准对比 |
| 相关性 | 响应满足用户意图并提供可操作见解 |
| 一致性 | 跟踪重复查询的变异性 |
| 延迟和效率 | 测量响应时间,确保满足企业操作要求 |
| 用户反馈 | 收集团队或用户的定性输入,优化模型 |
你通过科学的评估和持续优化,能够确保大模型自动填写系统始终保持高效、合规和安全。
你通过大模型自动填写,显著提升跨境汇款合规申报的效率,降低操作风险,强化合规保障。未来,你可以关注模型精度提升和流程智能化升级。行业趋势表明,ISO 20022结构化数据、端到端可追溯性和自动化处理将推动合规自动化广泛应用。你在落地实践时,可参考以下建议:
- 集中合规数据与监控,实施基于风险的分层管理
- 利用人工智能进行客户尽职调查和交易监控
- 改进制裁筛查流程,自动编制报告与表格
FAQ
大模型自动填写跨境汇款合规申报单据的主要优势是什么?
你可以显著提升申报效率,降低人工错误率,实现合规流程自动化。系统支持多语言和多币种,适配不同国家监管要求,提升整体合规水平。
如何保障数据安全与隐私?
你可以通过端到端加密、访问权限控制和数字身份验证,确保敏感信息在传输和存储过程中的安全。系统支持合规的数据隔离和审计追踪,防止数据泄露。
系统如何应对不同国家和地区的合规要求?
你可以依赖大模型自动加载和更新各地最新合规政策,自动调整申报字段和格式。系统支持ISO、SWIFT等国际标准,确保申报材料一次性通过审查。
是否可以与现有业务系统无缝集成?
你可以通过API接口或定制化集成方案,将自动填写系统与现有ERP、支付、风控等平台对接,实现端到端自动化处理,提升整体运营效率。
BiyaPay在跨境支付和合规自动化中的应用有哪些?
你可以使用BiyaPay实现全球支付与汇款、法币与加密货币实时兑换、USDT与USD或HKD兑换,以及美股、港股交易资金的便捷存取,满足多元化合规需求。
*This article is provided for general information purposes and does not constitute legal, tax or other professional advice from BiyaPay or its subsidiaries and its affiliates, and it is not intended as a substitute for obtaining advice from a financial advisor or any other professional.
We make no representations, warranties or warranties, express or implied, as to the accuracy, completeness or timeliness of the contents of this publication.
Related Blogs of

IGV 成分股有哪些?微软、Salesforce、Oracle 与 ServiceNow 权重和 AI 风险


Kevin Warsh 的政策框架是什么?对美元、美债和科技股有何影响




Choose Country or Region to Read Local Blog

Contact Us









