- More
- Download
Run Local Large Models or Call APIs? 2026 AI Development Cost and Payment Method Comparison





Image Source: unsplash
In high-frequency, long-term, and data-sensitive scenarios, choosing local large models is usually more cost-effective. API calls are better suited for short-term, testing, or elastic needs. In 2026, the cost structure and payment methods for AI development determine your return on investment. You need to focus on core comparison points such as model selection, interaction volume, prompt efficiency, API features, and usage scale:
| Cost Factor | Description |
|---|---|
| Model Selection | Advanced models cost more. |
| Interaction Volume | The more tokens used, the higher the cost. |
| Prompt Efficiency | Lengthy or repetitive prompts waste tokens. |
| API Features | API providers may offer cost-saving options. |
| Usage Scale | Chatbots processing millions of tokens monthly may cost $500–$5,000+. |
With the question “How to choose the AI development solution that best fits your needs,” let’s dive into a detailed comparison analysis.
Key Takeaways
- Choosing local large models is suitable for handling sensitive data, ensuring information security and avoiding data leaks.
- API calls are suitable for short-term projects, enabling quick integration of AI capabilities and lowering development barriers and initial investment.
- With high-frequency calls, the marginal cost of local large models gradually decreases, making them suitable for long-term operations.
- API calls use pay-as-you-go billing, flexibly handling usage fluctuations and suiting elastic demand.
- Combine your own business needs to reasonably choose between local large models or API calls to improve the cost-effectiveness of AI development.
Overall Conclusions and Scenarios
Scenarios Suitable for Local Large Models
You are more suitable to choose local large models in the following types of scenarios:
- You need to handle highly sensitive data, such as financial reports, medical records, or content involving personal privacy. Keeping data within the local environment maximizes information security.
- You focus on long-term operational costs. As inference volume increases, the marginal cost of local large models gradually decreases, offering greater cost advantages especially in high-frequency calls or large-scale deployments.
- You need offline availability. Whether on a flight or in an environment with unstable network, local large models ensure service continuity without reliance on external networks.
Local large models provide you with higher data control and flexibility, suitable for enterprises or developers with strict requirements for security, cost, and availability.
Scenarios Suitable for API Calls
You are more suitable to choose API calls in the following scenarios:
- You need rapid integration of AI capabilities, or in short-term projects and prototype testing phases, API calls can significantly lower development barriers and initial investment.
- You want the AI system to automatically adapt to compliance policies or changes in business rules. API service providers usually continuously update models to help you address compliance challenges.
- You need real-time monitoring and continuous compliance checks. API calls support automatic identification of new risks and timely detection of potential issues, suitable for industries like finance and law with high compliance requirements.
API calls bring you higher flexibility and scalability, suitable for elastic demand and fast-iteration business scenarios.
Quick Selection Guide
You can refer to the following quick reference table to rapidly determine which solution better suits your business:
| Demand Type | Recommended Solution |
|---|---|
| High-frequency / Long-term / Sensitive Data | Local Large Models |
| Short-term / Testing / Elastic Demand | API Calls |
| Offline Availability | Local Large Models |
| Dynamic Compliance Changes | API Calls |
| Quick Launch | API Calls |
You need to flexibly choose between local large models or API calls based on your own business needs, data sensitivity, budget, and technical capabilities to improve the cost-effectiveness and controllability of AI development.
Cost Comparison

Image Source: pexels
Local Large Model Costs
When deploying local large models, you first need to consider the high investment in hardware procurement, system setup, and ongoing maintenance. Taking enterprise-level applications as an example, the recommended cloud host instance costs nearly $38 per hour, with annual operating costs reaching $327,360. You also bear expenses for graphics cards, storage, cooling, and other hardware procurement, as well as subsequent system maintenance and upgrade costs. The table below summarizes the main cost types for local large models:
| Method | Cost Type | Description |
|---|---|---|
| Self-hosted LLM | High infrastructure and maintenance costs | Requires significant hardware investment and ongoing maintenance costs; for example, AWS recommended instances cost nearly $38 per hour, with annual costs up to $327,360. |
You also need to pay attention to the scalability of local large models. As inference volume increases, per-inference costs gradually decrease, making them suitable for high-frequency, large-scale scenarios. In industries with data sensitivity and high compliance requirements, you often prefer local deployment to achieve higher data control and security.
API Call Costs
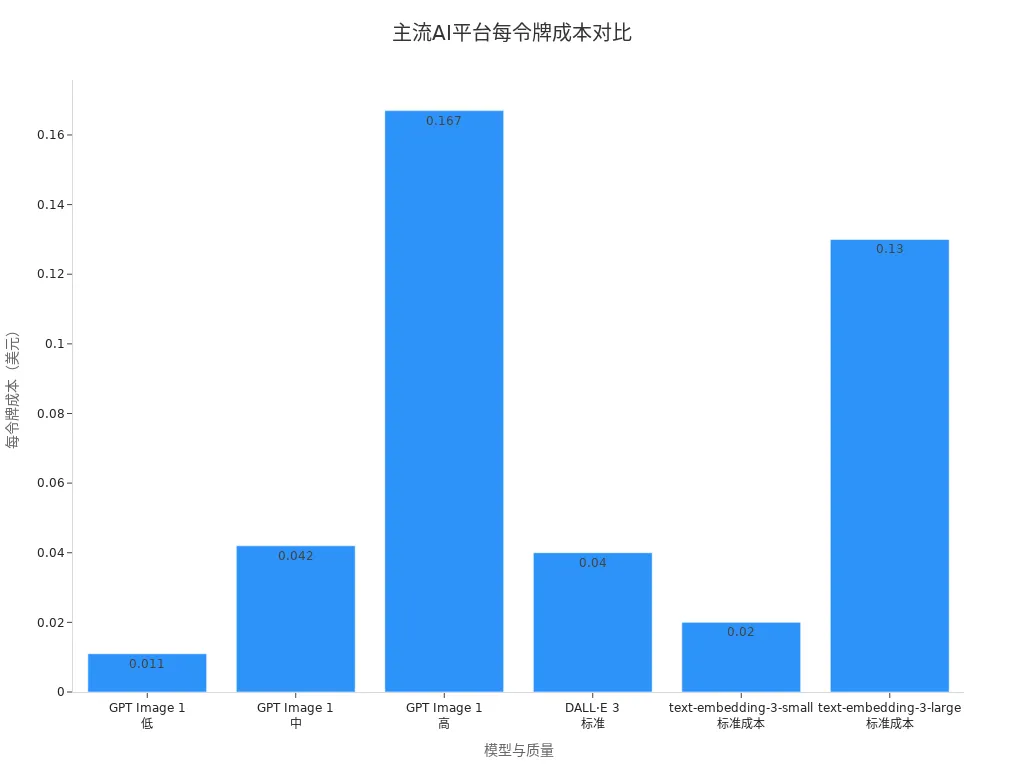
API calls adopt a pay-as-you-go model, where developers pay based on actual usage without bearing the complexity of infrastructure management. Taking OpenAI as an example, the ChatGPT API charges per token, and developers only pay for tokens sent or received, with a detailed and transparent pricing structure. You can refer to the table below to understand the per-token costs of different models on mainstream AI platforms:
| Model | Quality | Per Token Cost (USD) |
|---|---|---|
| GPT Image 1 | Low | $0.011 |
| GPT Image 1 | Medium | $0.042 |
| GPT Image 1 | High | $0.167 |
| DALL·E 3 | Standard | $0.04 |
| text-embedding-3-small | Standard | $0.02 |
| text-embedding-3-large | Standard | $0.13 |
In 2026, when using flagship models (such as GPT-5 and its variants), the price per million tokens usually remains in the low single-digit dollar range. The advantage of API calls lies in extremely low initial investment, suitable for short-term projects, prototype testing, and elastic demand. You can flexibly scale according to business volume without worrying about hardware depreciation and maintenance.
In scenarios such as global collections and payments, international remittances, and real-time digital currency exchange, you often need to call APIs to achieve multi-currency settlement and cross-border payments. For example, BiyaPay supports USDT exchange to USD or HKD and provides deposit/withdrawal services for U.S. stocks and Hong Kong stocks. By integrating BiyaPay via API, you can achieve automated fund flows and real-time exchange rate acquisition with pay-per-use billing, clear cost structure, and easy cost control.
API call costs also change with increased usage. In enterprise-level applications, you need to pay attention to the following three types of costs:
- Thinking and planning costs: related to the agent’s thinking-action-observation process; improper use may cause costs to rise rapidly.
- Orchestration and tool execution costs: involving multi-agent collaboration, external API calls, etc.; reasonable design is needed to reduce unnecessary expenses.
- Agent management costs: including expenses for monitoring, logging, and behavior management tools.
Hidden and Optimization Costs
When choosing local large models, you need to beware of hidden costs. Hardware power consumption, cooling systems, maintenance and repairs, learning curves and time investment, hardware depreciation, etc., all significantly affect the total cost of ownership. The table below shows common hidden cost types and estimates:
| Hidden Cost Type | Specific Content | Estimated Cost (USD) |
|---|---|---|
| Power Cost | CPU power consumption, system idle power, cooling system, PSU efficiency, etc. | $20-50/month |
| Maintenance and Repairs | Fan replacement, thermal paste, PSU upgrade, storage upgrade, unexpected failures, etc. | $150-400/year |
| Learning Curve and Time Investment | Initial setup, driver management, troubleshooting, OS management, etc. | $250-650/month |
| Depreciation and Obsolescence | Hardware value loss, technological progress, VRAM requirements, resale challenges, etc. | $400-600/year |
In API calls, hidden costs mainly lie in request design, prompt optimization, and multi-model collaboration. You can optimize overall costs through the following strategies:
- Semantic caching: use high-performance vector databases to store and retrieve answered questions, reducing 60% to 80% of duplicate traffic.
- Request merging: when multiple users ask the same question in a short time, merge into one API call to reduce latency and costs.
- Cascading routing: prioritize low-cost models, upgrade to high-quality models only when confidence is insufficient.
- Strict prompt compression: reduce redundant input tokens through relevance filtering and semantic summarization.
- Monitoring and financial optimization: track costs for each feature, model, and route; continuously A/B test and dynamically adjust strategies.
In scenarios such as global collections and payments and digital currency exchange, when using BiyaPay API, you can also further reduce API call costs and improve overall fund flow efficiency by optimizing request frequency and data structure.
Payment Methods
Local Large Model Payment Models
When deploying local large models, you need to pay attention to various payment models. One-time investment is the most common method, including hardware procurement, system setup, and initial configuration. You can also choose open-source models, which usually require no licensing fees but may involve subsequent maintenance and upgrade costs. Commercial licensing models require payment of proprietary license fees to obtain higher performance or more comprehensive technical support. Some vendors adopt dual licensing models, offering both open-source versions and proprietary licenses to fund development. Open-core models allow free use of basic functions, with additional features requiring payment. Software-as-a-Service models charge via subscription, suitable for enterprises needing continuous technical support. Freemium models provide basic services for free, with premium features requiring extra payment. Sponsorship and crowdfunding models rely on user donations or crowdfunding to support development. The table below summarizes mainstream local large model payment models and typical examples:
| Model Type | Description | Example |
|---|---|---|
| Dual Licensing | Software released under open-source license while also offering proprietary licenses to fund development. | MySQL |
| Open-Core Model | Provides open-source version of basic functions; additional features obtained via payment. | N/A |
| Software as a Service | No direct software charge; instead charges subscription for platform and tool usage. | N/A |
| Freemium | Basic service free; value-added services charged. | N/A |
| Sponsorship and Crowdfunding | Supports software development through user donations or crowdfunding. | N/A |
When choosing local large models, you need to comprehensively consider one-time investment versus long-term maintenance costs. In high-frequency, large-scale scenarios, initial investment can achieve break-even within months through marginal cost reduction. Open-source models provide significantly cost-effective alternatives, with performance gaps smaller than hardware cost differences. You also need to pay attention to additional costs such as embedding and vector database storage and retrieval fees, logging, monitoring, and auditing, which affect the overall budget.
API Billing Methods
When integrating AI capabilities, API billing methods are more flexible. Mainstream APIs adopt various methods such as usage-based billing, tiered pricing, transaction fees, revenue sharing, and subscription models. Usage-based billing suits scenarios with large usage fluctuations; tiered pricing provides package choices for different scales. Transaction fee models directly tie to business outcomes, suitable for high-value transaction scenarios. Revenue sharing models apply to business-driven APIs; subscription models provide predictable regular expenses. The table below shows mainstream API billing methods and applicable scenarios:
| Billing Method | Description | Applicable Scenario |
|---|---|---|
| Usage-based | Customers pay based on actual usage, suitable for large usage fluctuations. | Suitable for unstable usage patterns |
| Tiered Pricing | Provides different tiers; customers can choose plans suitable for their scale. | Suitable for customers with clear needs |
| Transaction Fees | Charge fees when API calls trigger high-value business behaviors, directly tied to business results. | Suitable for high-value transaction scenarios |
| Revenue Sharing | Provider receives a portion of revenue generated through the API. | Suitable for high-value business-driven scenarios |
| Subscription Model | Customers pay regular fees for access rights, usually including usage and overage fees. | Suitable for providers needing predictable revenue |
| Real-world Examples | Twilio API usually adopts usage-based billing; Google Maps API is similar. | Suitable for various service APIs |
When using BiyaPay API, you can pay per usage with a clear and transparent cost structure. BiyaPay supports global collections and payments, international remittances, real-time fiat and digital currency exchange, USDT to USD or HKD conversion, U.S. and Hong Kong stock trading deposits/withdrawals, and digital currency trading services. By integrating BiyaPay via API, you can achieve automated fund flows and real-time exchange rate acquisition, billed by actual transaction volume for easy cost control. Token-based billing enables precise tracking of usage, reducing scaling risks and avoiding surprise bills. You can also choose tiered packages and flexibly adjust according to business scale to meet needs at different stages.
If your AI cost planning also involves cross-border subscriptions, team payments, or multi-currency fund allocation, it helps to separate the payment layer from the model layer. In many cases, the real issue is not only the API bill itself, but whether the settlement path is stable, the conversion cost is transparent, and later reconciliation stays manageable. In that context, you can first use BiyaPay’s exchange rate and conversion tool to estimate the actual payment cost across currencies, then arrange the payment path through its virtual card application or remittance service if needed.
From a treasury perspective, BiyaPay is easier to understand as a multi-asset wallet covering cross-border payments, trading, and fund management scenarios. That makes it useful when software procurement, account top-ups, and later fund movement need to be handled within one workflow. If compliance and operating stability matter to your evaluation, its public information on the official website or updates in the event center can also serve as a reference point for long-term cost planning.
Cost Controllability
In the AI development process, cost controllability is at the core of decision-making. Local large models with one-time investment provide long-term cost predictability, suitable for high-traffic processing needs. You can compare the total cost of ownership between local open-source models and commercial APIs through a cost-effectiveness analysis framework. Mathematical models show that local deployment is economically feasible in high-frequency scenarios, usually achieving break-even within months. You can also optimize API call costs through strategies such as active caching, monitoring retrieval system costs, implementing user quotas and rate limits, and tracking costs per feature. API billing is flexible and suitable for short-term and elastic demand, but complex pricing structures may lead to budget uncertainty. When choosing an API Gateway, you need to focus on pricing models and applicability. For example, AWS API Gateway adopts usage-based billing, suitable for low-traffic organizations but with complex pricing; Kong API Gateway charges per million API requests, suitable for SMEs with predictable cost structure. You also need to pay attention to additional costs for embedding generation, reranking, and post-processing models, which affect the overall budget.
In high-frequency, large-scale scenarios, it is recommended to prioritize local large models to achieve long-term cost controllability; for short-term and elastic demand, choose API calls combined with tiered packages and real-time monitoring to optimize cost structure. BiyaPay API provides services such as global collections and payments, international remittances, and real-time digital currency exchange with pay-per-use billing, transparent cost structure, and easy budget management.
Scenario Selection
Enterprise vs. Individual
When choosing between local large models or API calls, the needs of enterprises and individual developers differ significantly. Enterprises usually focus more on data privacy, cost controllability, and model customization capabilities. You need to ensure sensitive data does not leak externally, eliminate ongoing cloud service fees, and flexibly adjust model parameters according to business scenarios. Individual developers tend toward ease of use and low cost, with stronger experimental needs. The table below summarizes the main demand differences between enterprises and individuals in AI development:
| Demand Type | Enterprise Developer Needs | Individual Developer Needs |
|---|---|---|
| Data Privacy | Complete privacy, suitable for handling sensitive data | May pay less attention to data privacy |
| Cost Savings | Eliminate ongoing cloud service fees | More focused on free or low-cost solutions |
| Customization Capability | Able to customize models for specific tasks | More focused on ease of use and experimentation |
| Control | Full control over model operation and configuration | Tend toward open-source model experimentation |
As an enterprise developer, you often find that large public models themselves have limited value for private companies. You need to deeply integrate models with your own data, with 95% of the work focused on data integration and business adaptation. Individual developers are more suitable for quick trial-and-error via APIs to lower technical barriers.
Privacy and Control
Your needs in data privacy and control directly influence the choice between local large models and API calls. When deploying local AI models, you can ensure all data is processed locally, with data never leaving the user device, greatly enhancing privacy protection and avoiding leaks during transmission. In regulated industries such as finance, healthcare, and law, you often need to strictly comply with international requirements like GDPR and CCPA. Local model deployment helps you better control data flows, meet compliance requirements, and improve data security and cost predictability. In unstable networks, flights, or remote areas, you can also obtain instant responses and higher data control through local AI. In contrast, API calls require sending data to the cloud for processing; although convenient, they carry certain privacy and compliance risks.
In scenarios such as global collections and payments, international remittances, and real-time fiat and digital currency exchange, if you have extremely high privacy requirements for fund flows and sensitive information, prioritize local model deployment. When integrating global payment and digital currency exchange services via BiyaPay API, you need to combine your own compliance strategy to reasonably choose data processing methods and ensure secure and compliant fund flows.
Development Efficiency
When pursuing development efficiency, API calls provide extremely high integration speed and flexibility. You can quickly access AI capabilities and focus on business logic without investing time in hardware deployment and environment configuration. API calls suit short-term projects, prototype testing, and elastic demand, helping shorten launch cycles and reduce trial-and-error costs. Although local large model deployment has higher initial investment, local inference usually offers faster single-request response speeds, especially when using quantized models and optimized runtime environments (such as llama.cpp). You can adjust prompt templates, benchmark different models, or debug outputs at any time without worrying about API rate limits or opaque pricing, greatly improving experimental efficiency.
In global fund flow and digital currency trading scenarios, integrating BiyaPay API enables automated operations and real-time exchange rate acquisition, further enhancing development efficiency and business response speed. You need to flexibly choose between local large models or API calls based on project cycle, team capabilities, and business needs to maximize development benefits.
Technical Barriers and Operations

Image Source: pexels
Technical Requirements for Local Large Models
When deploying local large models, you need strong technical capabilities and system planning awareness. You must reasonably plan infrastructure based on business needs, balancing performance and hardware budget. Modern lightweight AI models can now run efficiently on consumer-grade hardware, but enterprise-level applications still require consideration of higher memory and scalability. You can refer to the table below to understand the main technical requirements for local large model deployment in 2026:
| Technical Requirement | Detailed Description |
|---|---|
| Infrastructure Planning | You need to balance performance needs with hardware limitations and choose appropriate servers or cloud resources. |
| Deployment Tools | Container orchestration tools like Docker and Kubernetes support cross-node deployment for load balancing and high availability. |
| Memory Requirements | 7B models require 4-6GB RAM, 8B models require 6-10GB; enterprise deployments suggest reserving 50-100% redundant memory. |
| Security | You need to implement network isolation, access control, audit logs; API endpoints require authentication and rate limiting. |
| Monitoring Implementation | You should monitor system metrics such as CPU, memory, response time, as well as business metrics like accuracy and user satisfaction. |
You also need to regularly evaluate hardware depreciation and technological upgrades to ensure long-term stable system operation. For high-concurrency or extremely high request volumes (such as over 50 million tokens monthly), local deployment offers greater advantages in economics and compliance.
API Ease of Use
When integrating APIs, technical barriers are significantly reduced. You only need to call standard interfaces without worrying about underlying hardware and operations details. API service providers continuously optimize models and infrastructure to help you quickly launch new features. You can simplify the development process in the following ways:
- Choose mainstream API platforms and use rich documentation and SDKs to quickly achieve business integration.
- Use online tools to evaluate the cost-effectiveness of APIs versus local deployment to assist decision-making.
- Adopt tiered packages and token-based billing to flexibly control budgets.
In small-scale audio transcription, text processing, and other tasks, API integration can significantly improve development efficiency and avoid the complexity of local deployment.
Stability Comparison
When pursuing system stability, you need to weigh the differences between local deployment and API calls. Local large model deployment can achieve low latency and high availability, especially suitable for scenarios with extremely high response speed requirements. You can improve system fault tolerance through container orchestration and load balancing. API calls rely on external service providers and are greatly affected by network and platform stability, but they usually feature global multi-node redundancy and automatic scaling capabilities. In high-concurrency, large-scale text processing, APIs offer better unit economics but require attention to the service provider’s SLA and throttling policies.
You should reasonably choose local large model or API integration solutions based on business scale, technical capabilities, and stability needs to ensure long-term efficient system operation.
Long-term Trends and Cost-Effectiveness
Cost Change Trends
When planning AI development solutions in 2026, you must pay attention to the dynamic changes in cost structure. As AI model inference efficiency improves and hardware prices gradually decline, the marginal cost of local large models continues to decrease. You can scientifically judge when local deployment becomes more economical through cost-effectiveness analysis frameworks. In high-frequency scenarios, local deployment can achieve break-even within months. You also need to note that factors such as model complexity, input/output token count, request frequency, and geographic deployment area directly affect API call costs. Some cloud providers offer volume discounts for high-usage customers, but in large-scale applications, API costs can still rise rapidly. In long-term operations, you need to continuously evaluate the total cost of ownership for local deployment versus API calls and flexibly adjust strategies.
Impact of Technological Evolution
The rapid evolution of AI technology is reshaping the cost-effectiveness of local large models and API calls. You will find that cloud services provide the latest models and convenient integration experiences, but in terms of data privacy and long-term costs, organizations are more inclined to explore local open-source models. When choosing deployment methods, you must weigh model performance, compliance requirements, and maintenance complexity. Technological progress drives faster local model inference speeds and lower hardware barriers, prompting more enterprises to adopt hybrid deployment strategies. You can combine your own business needs and use open-source frameworks and automated operations tools to improve system flexibility and controllability.
Payment Model Outlook
In future AI service procurement, you will face more diverse and refined payment models. According to industry trends, AI features will adopt advanced pricing, with SaaS spending continuing to grow. You will encounter billing based on tasks, tokens, or conversations, and compliance costs will significantly influence service pricing. The popularity of open-source AI frameworks brings flexibility, but hidden costs and licensing management complexity increase simultaneously. You need to focus on budget fluctuations and total cost of ownership to reasonably plan AI investments. The table below summarizes changes in mainstream AI service payment models in 2026:
| Predicted Change | Description |
|---|---|
| Advanced Pricing | AI features adopt higher-tier pricing to increase service value |
| Usage-based Billing | Billing becomes more refined: per task, token, or conversation |
| Compliance Cost Impact | Compliance requirements drive adjustments to service pricing and payment models |
| Increased Open-Source Dependency | Open-source frameworks become widespread, but beware of hidden costs |
| Licensing and Renewal Complexity | Licensing management and renewal processes become more complex |
| Budget Fluctuations | Consumption-based pricing leads to unstable budgets, affecting innovation pace |
| Increased SaaS Spending | Annual SaaS spending continues to rise; optimize procurement and management |
When choosing AI development solutions, you should flexibly adjust based on your business scale, compliance needs, and budget to continuously optimize cost-effectiveness.
When choosing between local large models or API calls, you need to focus on core differences in costs, payment methods, and applicable scenarios. Local large models suit high-frequency, sensitive data, and long-term operations, while API calls are better for elastic demand and rapid integration. The table below shows API cost indices and usage shares for different task categories:
| Task Category | API Cost Index | Usage Share |
|---|---|---|
| Occupation Category 1 | 0.75 | 30% |
| Occupation Category 2 | 1.00 | 50% |
| Occupation Category 3 | 1.25 | 20% |
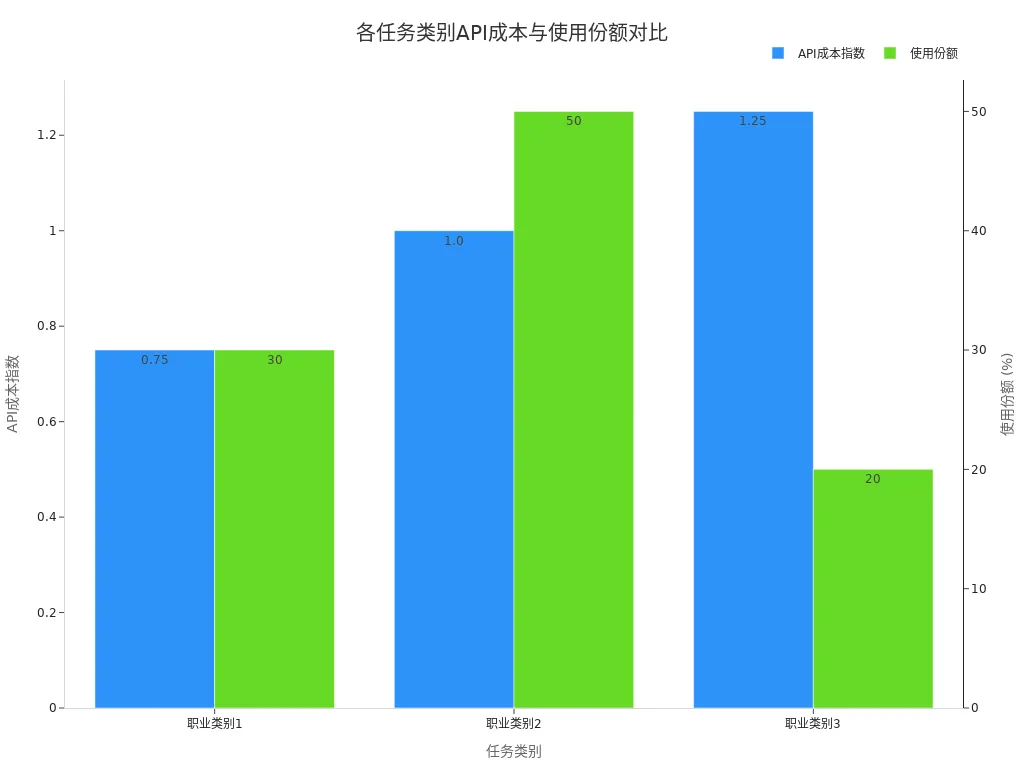
You can see that for every 1% increase in API cost, usage frequency decreases by 0.29%; for every 10% cost reduction, usage only increases by about 3%. In the future, AI development solutions will continue to optimize cost-effectiveness. You should flexibly choose the AI development path that best suits you based on actual business needs, budget, and technical capabilities.
FAQ
What hardware configuration is required for local large model deployment?
You need to select hardware based on model scale. 7B parameter models suggest 8GB+ VRAM; enterprise-level applications recommend high-performance GPUs and ample memory to ensure inference efficiency and stability.
How to control cost risks in API calls?
You can set budget caps, monitor call frequency, adopt tiered packages or token-based billing, and use real-time monitoring tools to promptly detect abnormal consumption and ensure costs remain controllable.
How to choose when data privacy requirements are high?
You should prioritize local large model deployment. Data is processed entirely locally, avoiding transmission to external servers and meeting compliance and security needs in industries like finance and healthcare.
What are the differences in development efficiency between local deployment and API calls?
You can quickly integrate AI capabilities via API calls to shorten launch cycles. Choosing local deployment requires more time for environment setup and system maintenance, suitable for long-term projects.
How to evaluate long-term cost advantages?
You need to combine inference frequency, data sensitivity, and business scale to calculate the total cost of ownership for local deployment versus cumulative API costs and select the more cost-effective solution.
*This article is provided for general information purposes and does not constitute legal, tax or other professional advice from BiyaPay or its subsidiaries and its affiliates, and it is not intended as a substitute for obtaining advice from a financial advisor or any other professional.
We make no representations, warranties or warranties, express or implied, as to the accuracy, completeness or timeliness of the contents of this publication.
Related Blogs of

AI Revenue Quality at IBM, Oracle, and ServiceNow: Breaking Down Subscription, Cloud, and Consulting Businesses


Are SMH, SOXX, and Hardware Leaders Absorbing Outflows from Software Stocks?


What Is Kevin Warsh’s Policy Framework? How It Affects the U.S. Dollar, Treasuries, and Tech Stocks


What Are IGV’s Holdings? Microsoft, Salesforce, Oracle, ServiceNow Weights and AI Risks

Choose Country or Region to Read Local Blog

Contact Us









